Autoscaling in Qubole Clusters¶
What Autoscaling Is¶
Autoscaling is a mechanism built in to QDS that adds and removes cluster nodes while the cluster is running, to keep just the right number of nodes running to handle the workload. Autoscaling automatically adds resources when computing or storage demand increases, while keeping the number of nodes at the minimum needed to meet your processing needs efficiently.
How Autoscaling Works¶
When you configure a cluster, you choose the minimum and maximum number of nodes the cluster will contain (Minimum Worker Nodes and Maximum Worker Nodes, respectively). While the cluster is running, QDS continuously monitors the progress of tasks and the number of active nodes to make sure that:
- Tasks are being performed efficiently (so as to complete within an amount of time that is set by a configurable default).
- No more nodes are active than are needed to complete the tasks.
If the first criterion is at risk, and adding nodes will correct the problem, QDS adds as many nodes as are needed, up to the Maximum Worker Nodes. This is called upscaling.
If the second criterion is not being met, QDS removes idle nodes, down to the Minimum Worker Nodes. This is called downscaling, or decommissioning.
The topics that follow provide details:
- Types of Nodes
- Upscaling
- Downscaling
- Preemptible VM-based Autoscaling in Google Cloud Platform
- How Autoscaling Works in Practice
See also Autoscaling in Presto Clusters.
Types of Nodes¶
Autoscaling operates only on the nodes that comprise the difference between the Minimum Worker Nodes and Maximum Worker Nodes (the values you specified in the QDS Cluster UI when you configured the cluster), and affects worker nodes only; these are referred to as autoscaling nodes.
The Coordinator Node, and the nodes comprising the Minimum Worker Nodes, are the stable core of the cluster; they normally remain running as long as the cluster itself is running; these are called core nodes.
Preemptible VMs and On-demand Instances on GCP¶
Preemptible VM instances on GCP have the following characteristics:
- The cost for preemptible VMs is much lower than the cost for on-demand instances.
- The price is fixed, based on the instance type, and does not fluctuate. For details about the pricing of preemptible instances, see Google Compute Engine Pricing in the GCP documentation.
- GCP Compute Engine can terminate (preempt) your preemptible VMs at any time if it needs to use them for other tasks.
- Compute Engine always terminates preemptible VMs after they run for 24 hours, if not sooner. But certain actions reset the 24-hour counter for a preemptible VM, for instance, stopping and restarting the instance.
For more information, see Preemptible VM-based Autoscaling in Google Cloud Platform below.
Upscaling¶
Launching a Cluster¶
QDS launches clusters automatically when applications need them. If the application needs a cluster that is not running, QDS launches it with the minimum number of nodes, and scales up as needed toward the maximum.
Upscaling Criteria¶
QDS bases upscaling decisions on:
- The rate of progress of the jobs that are running.
- Whether faster throughput can be achieved by adding nodes.
Assuming the cluster is running fewer than the configured maximum number of nodes, QDS activates more nodes if, and only if, the configured SLA (Service Level Agreement) will not be met at the current rate of progress, and adding the nodes will improve the rate.
Even if the SLA is not being met, QDS does not add nodes if the workload cannot be distributed more efficiently across more nodes. For example, if three tasks are distributed across three nodes, and progress is slow because the tasks are large and resource-intensive, adding more nodes will not help because the tasks cannot be broken down any further. On the other hand, if tasks are waiting to start because the existing nodes do not have the capacity to run them, then QDS will add nodes.
Note
In a heterogeneous cluster, upscaling can cause the actual number of nodes running in the cluster to exceed the configured Maximum Worker Nodes. See Why is my cluster scaling beyond the configured maximum number of nodes?.
Disk Upscaling on Hadoop MRv2 GCP Clusters¶
Disk upscaling dynamically adds volumes to GCP VMs that are approaching the limits of their storage capacity. You can enable disk upscaling on Hadoop MRv2 clusters, including clusters running Spark and Tez jobs as well as those running MapReduce jobs.
When you enable disk upscaling for a node, you also specify:
- The maximum number of disks that QDS can add to a node (Maximum Data Disk Count on the Clusters page in the QDS UI).
- The minimum percentage of storage that must be available on the node (Free Space Threshold %). When available storage drops below this percentage, QDS adds one or more disks until free space is at or above the minimum percentage, or the node has reached its Maximum Data Disk Count. The default is 25%.
- The absolute amount of storage that must be available on the node, in gigabytes (Absolute Free Space Threshold). When available storage drops below this amount, QDS adds one or more disks until free space is at or above the minimum amount, or the node has reached its Maximum Data Disk Count. The default is 100 GB.
In addition, QDS monitors the rate at which running Hadoop jobs are using up storage, and from this computes when more storage will be needed.
QDS autoscaling adds storage but does not remove it directly, because this involves reducing the filesystem size, a risky operation. The storage is removed when the node is decommissioned.
Reducers-based Upscaling on Hadoop MRv2 Clusters¶
Hadoop MRv2 clusters can upscale on the basis of the number of Reducers. This configuration is disabled by default.
Enable it by setting mapred.reducer.autoscale.factor=1 as a Hadoop override.
Downscaling¶
QDS bases downscaling decisions on the following factors.
Downscaling Criteria¶
A node is a candidate for decommissioning only if:
The cluster is larger than its configured minimum size.
No tasks are running.
The node is not storing any shuffle data (data from Map tasks for Reduce tasks that are still running).
Enough cluster storage will be left after shutting down the node to hold the data that must be kept (including HDFS replicas).
Note
This storage consideration does not apply to Presto clusters.
See also Aggressive Downscaling.
Note
In Hadoop MRv2, you can control the maximum number of nodes that can be downscaled simultaneously
by setting mapred.hustler.downscaling.nodes.max.request to the maximum you want; the default
is 500.
Downscaling Exception for Hadoop 2 and Spark Clusters: Hadoop 2 and Spark clusters do not downscale
to a single worker node once they have been upscaled. When
Minimum Worker Nodes is set to 1, the cluster starts with a single worker node, but once upscaled, it never
downscales to fewer than two worker nodes. This is because decommissioning slows down greatly if there is only one usable
node left for HDFS, so nodes doing no work may be left running, waiting to be decommissioned. You can override this
behaviour by setting mapred.allow.single.worker.node to true and restarting the cluster.
Container Packing in Hadoop 2 and Spark¶
QDS allows you to pack YARN containers on Hadoop MRv2 (Hadoop 2) and Spark clusters.
Container packing is enabled by default for GCP clusters.
Container packing causes the scheduler to pack containers on a subset of nodes instead of distributing them across all the nodes of the cluster. This increases the probability of some nodes remaining unused; these nodes become eligible for downscaling, reducing your cost.
Packing works by separating nodes into three sets:
- Nodes with no containers (the Low set)
- Nodes with memory utilization greater than the threshold (the High set)
- All other nodes (the Medium set)
YARN schedules each container request in this order: nodes in the Medium set first, nodes in the Low set next, nodes in the High set last. For more information, see Enabling Container Packing in Hadoop 2 and Spark.
Graceful Shutdown of a Node¶
If all of the downscaling criteria are met, QDS starts decommissioning the node. QDS ensures a graceful shutdown by:
Waiting for all tasks to complete.
Ensuring that the node does not accept any new tasks.
Transferring HDFS block replicas to other nodes.
Note
Data transfer is not needed in Presto clusters.
Recommissioning a Node¶
If more jobs enter the pipeline while a node is being decommissioned, and the remaining nodes cannot handle them, the node is recommissioned – the decommissioning process stops and the node is reactivated as a member of the cluster and starts accepting tasks again.
Recommissioning takes precedence over launching new instances: when handling an upscaling request, QDS launches new nodes only if the need cannot be met by recommissioning nodes that are being decommissioned.
Recommissioning is preferable to starting a new instance because:
- It is more efficient, avoiding bootstrapping a new node.
- It is cheaper than provisioning a new node.
Dynamic Downscaling¶
Dynamic downscaling is triggered when you reduce the maximum size of a cluster while it’s running. The subsections that follow explain how it works. First you need to understand what happens when you decrease (or increase) the size of a running cluster.
Effects of Changing Worker Nodes Variables while the Cluster is Running: You can change the Minimum Worker Nodes and Maximum Worker Nodes while the cluster is running. You do this via the Cluster Settings screen in the QDS UI, just as you would if the cluster were down.
To force the change to take effect dynamically (while the cluster is running) you must push it, as described here. Exactly what happens then depends on the current state of the cluster and configuration settings. Here are the details for both variables.
Minimum Worker Nodes: An increase or reduction in the minimum count takes effect dynamically by default. (On a Hadoop
MRv2 cluster, this happens because mapred.refresh.min.cluster.size is set to true by default. Similarly, on a Presto
cluster, the configuration reloader mechanism detects the change.)
Maximum Worker Nodes:
- An increase in the maximum count takes effect dynamically.
- A reduction in the maximum count produces the following behavior:
- If the current cluster size is smaller than the new maximum, the change takes effect dynamically. For example, if the maximum is 15, 10 nodes are currently running and you reduce the maximum count to 12, 12 will be the maximum from now on.
- If the current cluster size is greater than the new maximum, QDS begins reducing the cluster to the new maximum, and subsequent upscaling will not exceed the new maximum. In this case, the default behavior for reducing the number of running nodes is dynamic downscaling.
How Dynamic Downscaling Works:
If you decrease the Maximum Worker Nodes while the cluster is running, and more than the new maximum number of nodes are actually running, then QDS begins dynamic downscaling.
If dynamic downscaling is triggered, QDS selects the nodes that are:
- closest to completing their tasks
- (in the case of Hadoop MRv2 clusters) closest to the time limit for their containers
Once selected, these nodes stop accepting new jobs and QDS shuts them down gracefully until the cluster is at its new maximum size (or the maximum needed for the current workload, whichever is smaller).
Note
In a Spark cluster, a node selected for dynamic downscaling may not be removed immediately in some cases– for example, if a Notebook or other long-running Spark application has executors running on the node, or if the node is storing Shuffle data locally.
Aggressive Downscaling¶
Aggressive Downscaling refers to a set of QDS capabilities that are enabled by default for GCP clusters. See Aggressive Downscaling for more information.
Shutting Down an Idle Cluster¶
By default, QDS shuts the cluster down completely if both of the following are true:
- There have been no jobs in the cluster over a configurable period.
- At least one node is close to its hourly boundary (not applicable if Aggressive Downscaling is enabled) and no tasks are running on it.
You can change this behavior by disabling automatic cluster termination, but Qubole recommends that you leave it enabled – inadvertently allowing an idle cluster to keep running can become an expensive mistake.
Preemptible VM-based Autoscaling in Google Cloud Platform¶
For clusters on GCP, you can create and run preemptible VMs for a much lower price than you would pay for on-demand instances.
In the QDS UI, you can configure a percentage of your instances to be preemptible. You do this via the Composition tab in either the New Cluster or Edit Cluster screen. In the Summary section, click edit next to Composition. The number you put in the Preemptible Nodes (%) field specifies the maximum percentage of autoscaling nodes that QDS can launch as preemptible VMs:
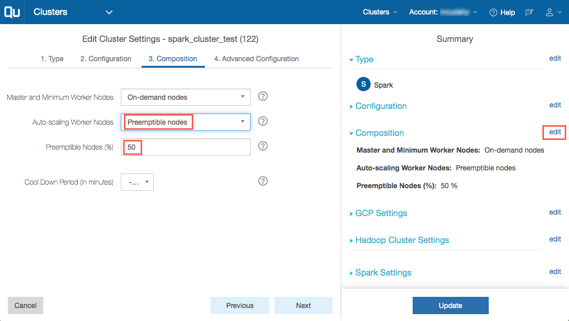
Qubole recommends using one of the following approaches to combining on-demand instances with preemptible VMs:
- Use on-demand instances for your core nodes and a combination of on-demand instances and preemptible VMs for the autoscaling nodes.
- Use preemptible VMs for both core nodes and autoscaling nodes.
Normally, the core nodes in a cluster are run on stable on-demand instances, except where an unexpected termination of the entire cluster is considered worth risking in order to obtain lower costs. Autoscaling nodes, on the other hand, can be preemptible without a risk that the cluster could be unexpectedly terminated. For more information on preemptible instances, see Preemptible VM Instances in the GCP documentation.
Rebalancing¶
Using preemptible VMs on GCP significantly reduces your cost, but fluctuations in the market may mean that QDS cannot always obtain as many preemptible instances as your cluster specification calls for. (QDS tries to obtain the preemptible instances for a configurable number of minutes before giving up.)
For example, suppose your cluster needs to scale up by four additional nodes, but only two preemptible instances that meet your requirements (out of the maximum of four you specified) are available. In this case, QDS will launch the two preemptible instances, and (by default) make up the shortfall by also launching two on-demand instances, meaning that you will be paying more than you had hoped in the case of those two instances. (You can change this default behavior in the QDS UI on the Add Cluster and Cluster Settings pages, by un-checking Fallback to on demand under the Cluster Composition tab.)
Whenever the cluster is running a greater proportion of on-demand instances than you have specified, QDS works to remedy the situation by monitoring the preemptible market, and replacing the on-demand nodes with preemptible instances as soon as suitable instances become available. This is called Rebalancing.
Note
Rebalancing is supported in Hadoop MRv2 and Spark clusters only.
How Autoscaling Works in Practice¶
Hadoop MRv2¶
Here’s how autoscaling works on Hadoop MRv2 (Hadoop 2 (Hive) clusters):
In Hadoop MRv2, you can control the maximum number of nodes that can be downscaled simultaneously by means of
mapred.hustler.downscaling.nodes.max.request. Its default value is 500.
- Each node in the cluster reports its launch time to the ResourceManager, which keeps track of how long each node has been running.
- YARN ApplicationMasters request YARN resources (containers) for each Mapper and Reducer task. If the cluster does not have enough resources to meet these requests, the requests remain pending.
- On the basis of a pre-configured threshold for completing tasks (for example, two minutes), and the number of pending requests, ApplicationMasters create special autoscaling container requests.
- The ResourceManager sums the ApplicationMasters’ autoscaling container requests, and on that basis adds more nodes (up to the configured Maximum Worker Nodes).
- Whenever a node approaches its hourly boundary, the ResourceManager checks to see if any task or shuffle process is running on this node. If not, the ResourceManager decommissions the node.
Note
- You can improve autoscaling efficiency by enabling container packing.
- You can control the maximum number of nodes that can be downscaled simultaneously
by setting
mapred.hustler.downscaling.nodes.max.requestto the maximum you want; the default is 500.
Presto¶
Autoscaling in Presto Clusters explains how autoscaling works in Presto.
Spark¶
Here’s how autoscaling works on a Spark cluster:
- You can configure Spark autoscaling at the cluster level and at the job level.
- Spark applications consume YARN resources (containers); QDS monitors container usage and launches new nodes (up to the configured Maximum Worker Nodes) as needed.
- If you have enabled job-level autoscaling, QDS monitors the running jobs and their rate of progress, and launches new executors as needed (and hence new nodes if necessary).
- As jobs complete, QDS selects candidates for downscaling and initiates Graceful Shutdown of those nodes that meet the criteria.
For a detailed discussion and instructions, see Autoscaling in Spark.
Note
You can improve autoscaling efficiency by enabling container packing.
Tez on Hadoop 2 (Hive) Clusters¶
Here’s how autoscaling works on a Hadoop 2 (Hive) cluster where Tez is the execution engine:
Note
Tez is not supported on all Cloud platforms.
- Each node in the cluster reports its launch time to the ResourceManager, which keeps track of how long each node has been running.
- YARN ApplicationMasters request YARN resources (containers) for each Mapper and Reducer task. If the cluster does not have enough resources to meet these requests, the requests remain pending.
- ApplicationMasters monitor the progress of the DAG (on the Mapper nodes) and calculate how long it will take to finish their tasks at the current rate.
- On the basis of a pre-configured threshold for completing tasks (for example, two minutes), and the number of pending requests, ApplicationMasters create special autoscaling container requests.
- The ResourceManager sums the ApplicationMasters’ autoscaling container requests, and on that basis adds more nodes (up to the configured Maximum Worker Nodes).
- Whenever a node approaches its hourly boundary, the ResourceManager checks to see if any task or shuffle process is running on this node. If not, the ResourceManager decommissions the node.
For More Information¶
For more information about configuring and managing QDS clusters, see: