Composing Spark Commands in the Analyze Page¶
Use the command composer on the Workbench page to compose a Spark command.
See Running Spark Applications and Spark in Qubole for more information. For information about using the REST API , see Submit a Spark Command.
Spark queries run on Spark clusters. See Mapping of Cluster and Command Types for more information.
Qubole Spark Parameters¶
- The Qubole parameter
spark.sql.qubole.parquet.cacheMetadataallows you to turn caching on or off for Parquet table data. Caching is on by default; Qubole caches data to prevent table-data-access query failures in case of any change in the table’s Cloud storage location. If you want to disable caching of Parquet table data, setspark.sql.qubole.parquet.cacheMetadatatofalse. You can do this at the Spark cluster or job level, or in a Spark Notebook interpreter.
- In case of DirectFileOutputCommitter (DFOC) with Spark, if a task fails after writing files partially, the subsequent reattempts might fail with FileAlreadyExistsException (because of the partial files that are left behind). Therefore, the job fails. You can set the
spark.hadoop.mapreduce.output.textoutputformat.overwriteandspark.qubole.outputformat.overwriteFileInWriteflags totrueto prevent such job failures.
Ways to Compose and Run Spark Applications¶
You can compose a Spark application using:
- Command Line. See Compose a Spark Application using the Command Line.
- Python. See Compose a Spark Application in Python.
- Scala. See Compose a Spark Application in Scala.
- SQL. See Compose a Spark Application in SQL.
Note
You can read a Spark job’s logs, even after the cluster on which it was run has terminated, by means of the offline Spark History Server (SHS). For offline Spark clusters, only event log files that are less than 400 MB are processed in the SHS. This prevents high CPU utilization on the webapp node. For more information, see this blog.
Note
You can use the --packages option to add a list of comma-separated Maven coordinates for external packages
that are used by a Spark application composed in any supported language. For example, in the
Spark Submit Command Line Options text field, enter --packages com.package.module_2.10:1.2.3.
Note
You can use macros in script files for Spark commands with subtypes scala (Scala), py (Python), R (R), sh (Command), and sql (SQL). You can also use macros in large inline content and large script files for scala (Scala), py (Python), R (R), @ and sql (SQL). This capability is not enabled for all users by default; create a ticket with Qubole Support
to enable it for your QDS account.
Compose a Spark Application in Scala¶
Perform the following steps to compose a Spark command:
Navigate to the Workbench page and click + Create New. Select the Spark tab near the top of the page. Scala is selected by default:
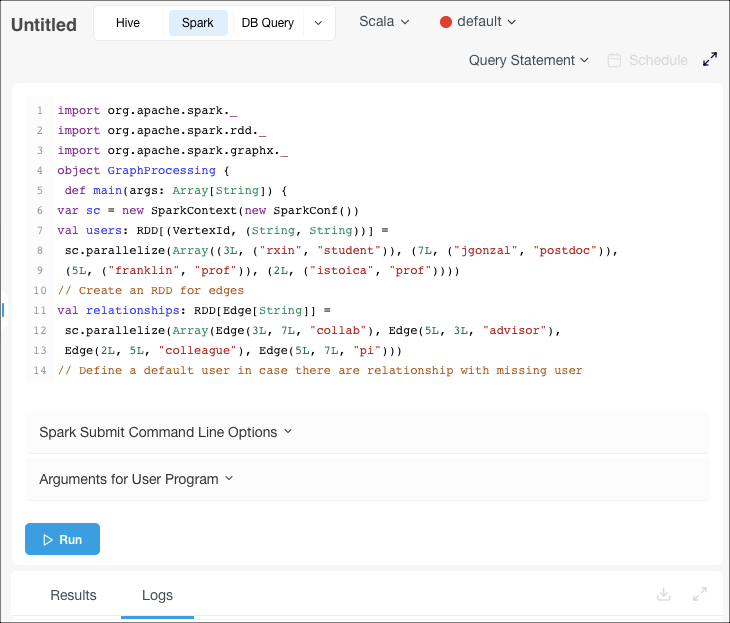
Either:
- To use a stored query, select Query Path from the drop-down list near the top right of the page, then specify the Cloud storage path that contains the query file.
Or:
- Enter your query in the text field (Query Statement is selected by default in the drop-down list near the top right of the page; this is what you want in this case).
Optionally enter command options in the Spark Submit Command Line Options field to override the defaults shown in the Spark Default Submit Command Line Options field.
Optionally specify arguments in the Arguments for User Program field.
Click Run to execute the query.
The query result appears the Results tab, and the query logs under the Logs tab. Note the clickable Application UI link to the Spark application UI under the Logs tab. See also Downloading Results and Logs.
Compose a Spark Application in Python¶
Perform the following steps to compose a Spark command:
Navigate to the Workbench page and click + Create New. Select the Spark tab near the top of the page.
Select Python from the drop-dowm menu (Scala is selected by default).
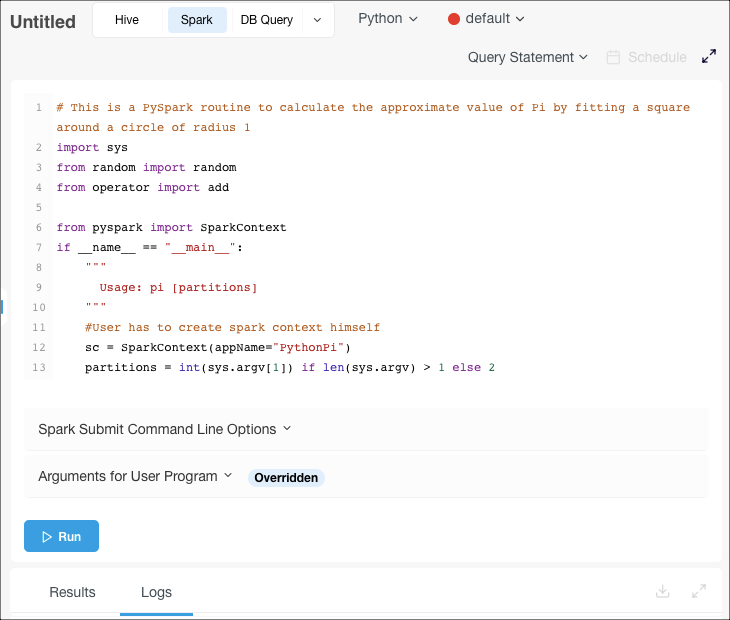
Either:
- To use a stored query, select Query Path from the drop-down list near the top right of the page, then specify the Cloud storage path that contains the query file.
Or:
- Enter your query in the text field (Query Statement is selected by default in the drop-down list near the top right of the page; this is what you want in this case).
Optionally enter command options in the Spark Submit Command Line Options field to override the defaults shown in the Spark Default Submit Command Line Options field. You can use the
--py-filesargument to specify remote files in a Cloud storage location, in addition to local files.Optionally specify arguments in the Arguments for User Program field.
Click Run to execute the query.
The query result appears under the Results tab, and the query logs under the Logs tab. Note the clickable Application UI link to the Spark application UI under the Logs tab. See also Downloading Results and Logs.
Compose a Spark Application using the Command Line¶
Note
Qubole does not recommend using the Shell command option to run a Spark application via Bash shell commands, because in this case automatic changes (such as increases in the Application Coordinator memory based on the driver memory, and the availability of debug options) do not occur. Such automatic changes do occur when you run a Spark application using the Command Line option.
Perform the following steps to compose a Spark command:
Navigate to the Workbench page and click + Create New. Select the Spark tab near the top of the page.
Select Command Line from the drop-dowm menu (Scala is selected by default).
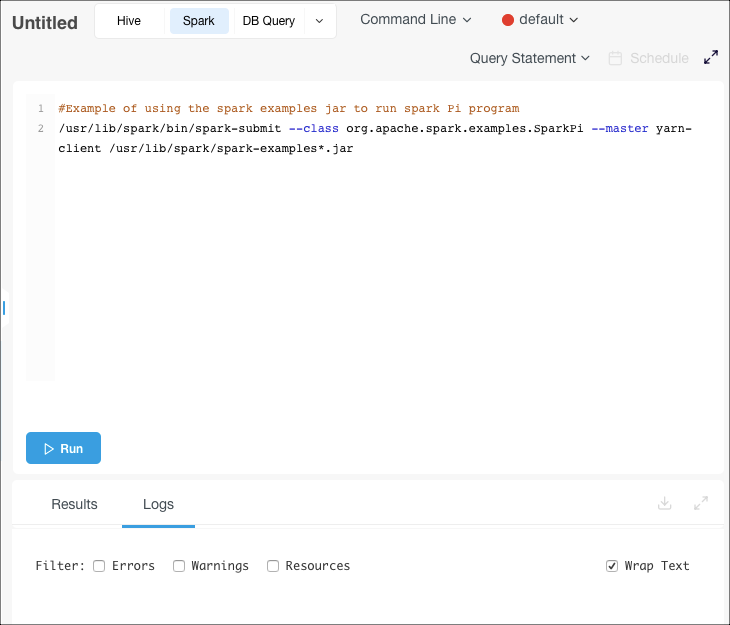
Click Run to execute the query.
The query result appears under the Results tab, and the query logs under the Logs tab. Note the clickable Application UI link to the Spark application UI under the Logs tab. See also Downloading Results and Logs.
Compose a Spark Application in SQL¶
Note
You can run Spark commands in SQL with Hive Metastore 2.1. This capability is not enabled for all users by default; create a ticket with Qubole Support to enable it for your QDS account.
Note
You can run Spark SQL commands with large script files and large inline content. This capability is not enabled for all users by default; create a ticket with Qubole Support to enable it for your QDS account.
Navigate to the Workbench page and click + Create New. Select the Spark tab near the top of the page.
Select SQL from the drop-dowm menu (Scala is selected by default).
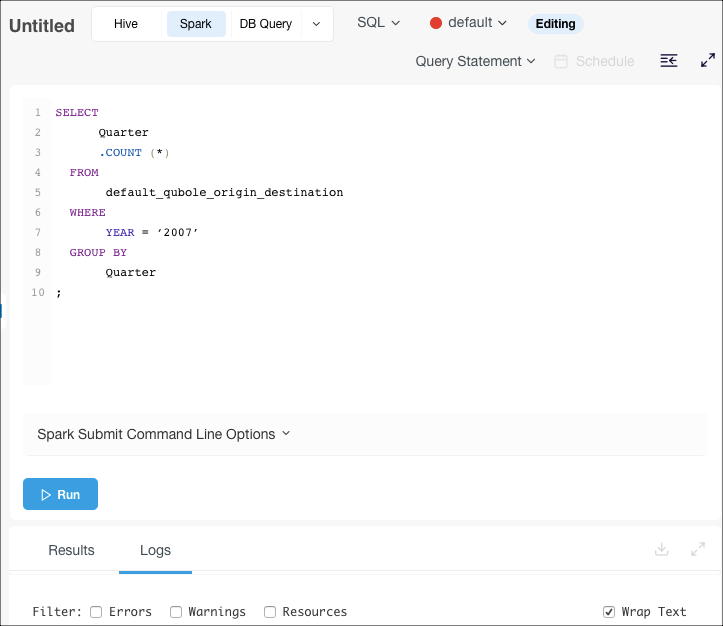
Either:
- To use a stored query, select Query Path from the drop-down list near the top right of the page, then specify the Cloud storage path that contains the query file.
Or:
- Enter your query in the text field (Query Statement is selected by default in the drop-down list near the top right of the page; this is what you want in this case).
Optionally enter command options in the Spark Submit Command Line Options field to override the defaults shown in the Spark Default Submit Command Line Options field.
Click Run to execute the query.
The query result appears under the Results tab, and the query logs under the Logs tab. Note the clickable Application UI link to the Spark application UI under the Logs tab. See also Downloading Results and Logs.
Compose a Spark Application in R¶
Perform the following steps to compose a Spark command:
Navigate to the Workbench page and click + Create New. Select the Spark tab near the top of the page.
Select R from the drop-dowm menu (Scala is selected by default).
Either:
- To use a stored query, select Query Path from the drop-down list near the top right of the page, then specify the Cloud storage path that contains the query file.
Or:
- Enter your query in the text field (Query Statement is selected by default in the drop-down list near the top right of the page; this is what you want in this case).
Optionally enter command options in the Spark Submit Command Line Options field to override the defaults shown in the Spark Default Submit Command Line Options field.
Optionally specify arguments in the Arguments for User Program field.
Click Run to execute the query.
The query result appears under the Results tab, and the query logs under the Logs tab. Note the clickable Application UI link to the Spark application UI under the Logs tab. See also Downloading Results and Logs.
Known Issue¶
In a cluster using preemptible nodes exclusively, the Spark Application UI may display the state of the application incorrectly, showing the application as running even though the coordinator node, or the node running the driver, has been reclaimed by GCP. The status of the QDS command will be shown correctly on the Workbench page. Qubole does not recommend using preemptible nodes only.