Configuring Interpreters in a Notebook¶
An interpreter enables using a specific language/data-processing backend. It is denoted by %<interpreter>. Notebooks
support Angular, Presto (on AWS and Azure for Presto clusters), Spark (pyspark, scala, sql, R, and knitr for Spark clusters), markdown, and shell as interpreters. You can
create any number of interpreter setting objects.
Interpreters are associated with a notebook. A specific cluster type provides its own type of interpreters.
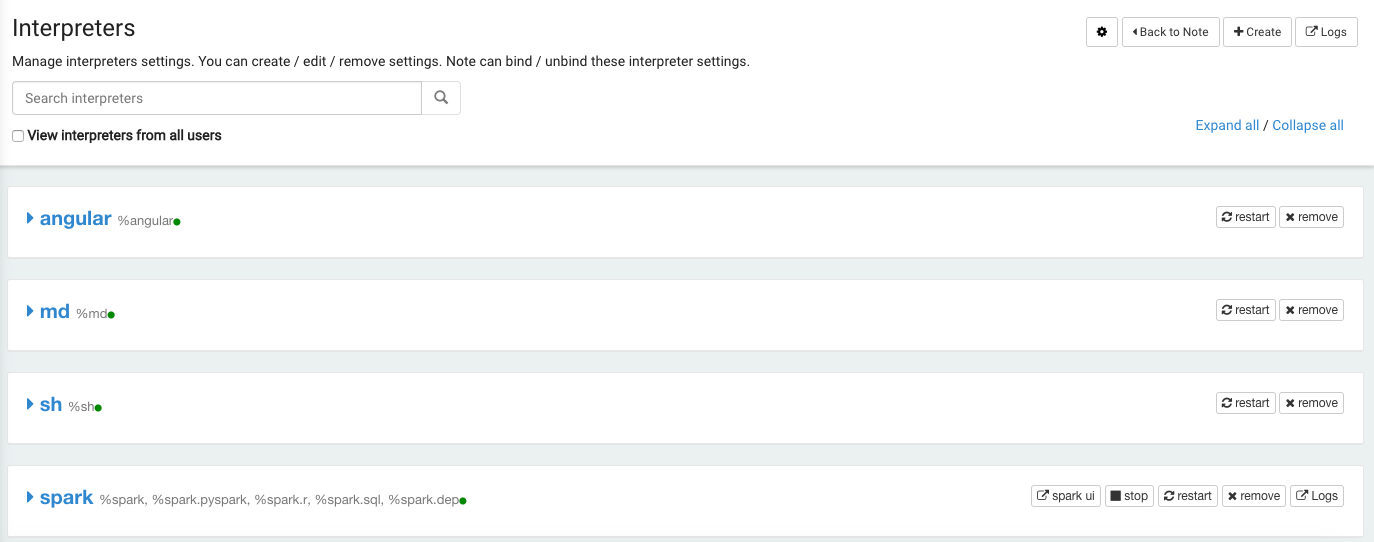
From a running notebook, click Interpreters to view the set of Interpreters.
Qubole provides the following set of default Interpreters for Spark notebooks:
%spark,%pyspark,%sparkr,%sql,%dep,%knitr, and%r.%sparkis useful in a Spark notebook.
Qubole notebooks now support expanding and collapsing the different intepreters. The expand/collapse button is as shown here.
For more information on how to use interpreters, see Associating Interpreters with Notebooks. Understanding Spark Notebooks and Interpreters and Configuring a Spark Notebook describe about the interpreter settings of a Spark notebook.
Using the Anaconda Interpreter¶
QDS supports using Anaconda IDE features using it as a Python interpreter on Qubole notebooks. One of the advantages of using Anaconda is it eases the Python installation compared to the pip tool.
The Anaconda Python interpreter is part of Qubole AMI. To use it in the notebook, change the zeppelin.pyspark.python
interpreter’s value to /usr/lib/anaconda2/bin/python.