Understanding Spark Cluster Worker Node Memory and Defaults¶
The memory components of a Spark cluster worker node are Memory for HDFS, YARN and other daemons, and executors for Spark applications. Each cluster worker node contains executors. An executor is a process that is launched for a Spark application on a worker node. Each executor memory is the sum of yarn overhead memory and JVM Heap memory. JVM Heap memory comprises of:
- RDD Cache Memory
- Shuffle Memory
- Working Heap/Actual Heap Memory
The following figure illustrates a Spark application’s executor memory layout with its components.
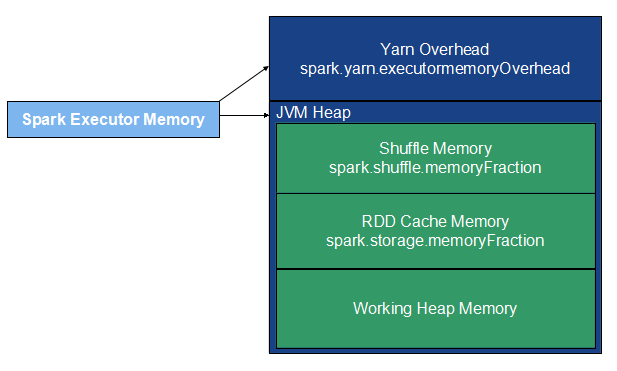
An example of a cluster worker node’s memory layout can be as follows. Let us assume total memory of a cluster slave node is 25GB and two executors are running on it.
5GB - Memory for HDFS, YARN and other daemons and system processes
10GB - Executor 1
2GB - yarn overhead (spark.yarn.executor.memoryOverhead 2048)
8GB - JVM heap size (spark.executor.memory 8GB):
4.8GB - RDD cache memory (spark.executor.storage.memoryFraction 0.6)
1.6GB - Shuffle memory (spark.executor.shuffle.memoryFraction 0.2)
1.6GB - Working heap
10GB - Executor 2
Understanding Qubole’s Default Parameters Calculation¶
Qubole automatically sets spark.executor.memory, spark.yarn.executor.memoryOverhead and spark.executor.cores on the cluster.
It is based on the following points:
- Avoid very small executors. There are many overheads involved and with very small executor-memory, the real available processing memory is too small. Large partitions may result in out of memory (OOM)issues.
- Avoid very large executors as they create trouble in sharing resources among applications. They also cause YARN to keep more resources reserved that results in under-utilising the cluster.
- Broadly set the memory between 8GB and 16GB. This is an arbitrary choice and governed by the above two points.
- Pack as many executors as can be assigned to one cluster node.
- Evenly distribute cores to all executors.
- If RAM per vCPU is large for some instance type, Qubole’s computed executor is also similar but the ratio of RAM per
number of executors (
--num-executors) and maximum number of executors (--max-executors) are set to 2. Hence, autoscaling is disabled by default. Maximum number of executors configuration (--max-executors) is preferred when there are lot of jobs in parallel that must share the cluster resources. Similarly, a Spark job can start with an exact number of executors (--num-executors) rather than depending on the default number of executors.
Assigning CPU Cores to an Executor¶
For example, consider a node has 4 vCPUs according to EC2, then YARN might report eight cores depending on the configuration. If you want to run four
executors on this node, then set spark.executor.cores to 2. This ensures that each executor uses 1 vCPU. Also, the
executor can run two tasks in parallel.
For more information about the resource allocation, Spark application parameters, and determining resource requirements, see An Introduction to Apache Spark Optimization in Qubole.