Why Qubole?¶
The rapidly increasing volume, velocity, and variety of data, and emerging analytics and machine learning tools and techniques have created the need for an open data lake architecture.
An open data lake provides a robust and future-proof data management paradigm to support a wide range of data processing needs, including data exploration, interactive analytics, and machine learning.
Qubole is an open and secure data lake platform for machine learning, streaming, and ad hoc analytics. The platform provides end-to-end services that reduce the time, effort, and cost required for running data pipelines, streaming analytics, and executing machine learning workloads on any cloud.
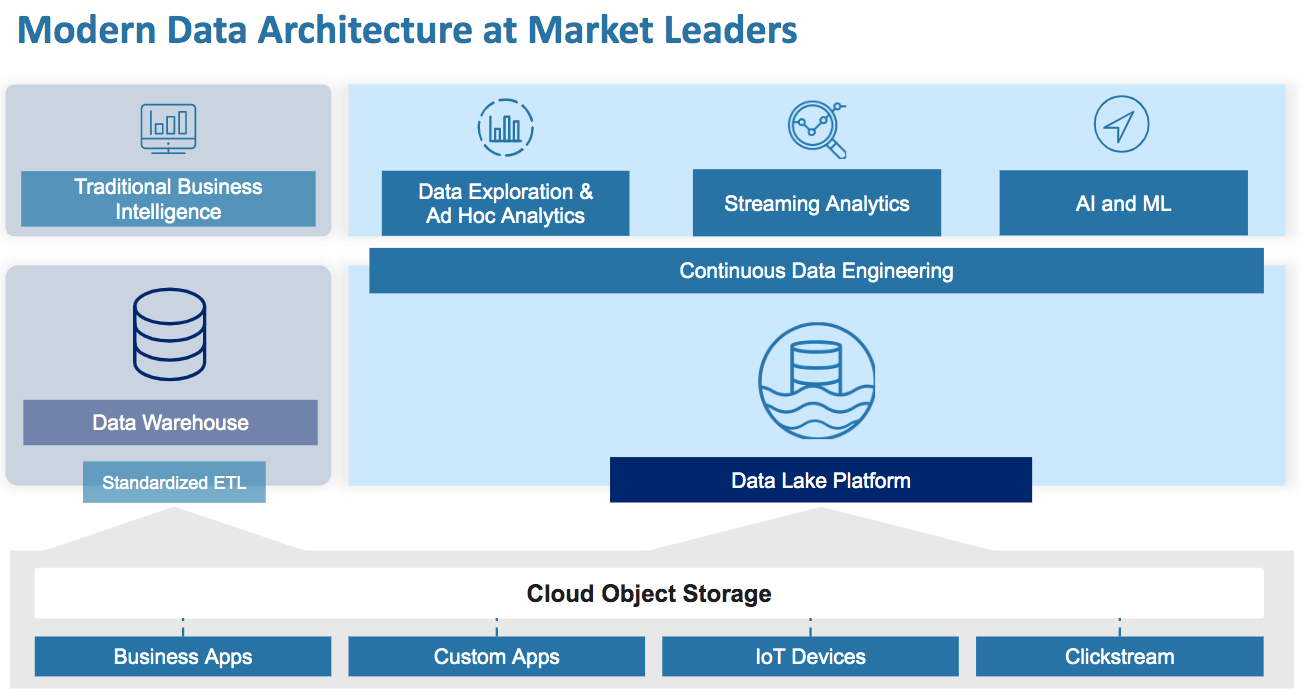
Machine learning (ML): Data lakes are ideal for machine learning use cases. They not only provide SQL-based access to data but also offer native support for programmatic distributed data processing frameworks such as Apache Spark and Tensorflow through Python, Scala, Java, and other languages. Qubole provides you with the capabilities to build, visualize, and collaborate on ML models. The platform’s ML-specific capabilities, such as offline editing, multi-language interpretation, and version control, deliver faster results. You can leverage Jupyter or Qubole notebooks to monitor application status and job progress, and use the integrated package manager to update the libraries at scale.
Ad hoc and streaming analytics: Streaming analytics enables the ingestion, processing, and analysis of data in real-time without requiring data to be stored for analysis. Data lakes support native streaming where data streams are processed and made available for analytics as they arrive. Data pipelines transform data as it is received from the data stream and trigger the computations required for analytics.
Qubole’s Workbench lets you author, save, collaborate, and share reports and queries. You can develop and deliver ad hoc SQL analytics through optimized ANSI/ISO-SQL (Presto, Hive, SparkSQL) and third-party tools such as Tableau, Looker, and Git native integrations. You can also build streaming data pipelines, combine with multiple streaming, and batch datasets to gain real-time insights.
Data engineering: Data lakes are suitable for use cases that require continuous data engineering. Qubole automates pipeline creation, scaling, and monitoring. You can easily create, schedule, and manage workloads while using the processing engine and language of your choice (Apache Spark, Hive, Presto with SQL, Python, R, or Scala).
The following Qubole blog posts provide more information: